手書き文字の豊富なデータとしてMNISTデータがありますが、今回はMNISTデータを機械学習し、文字を予測してみたいと思います。
アルゴリズムの選定
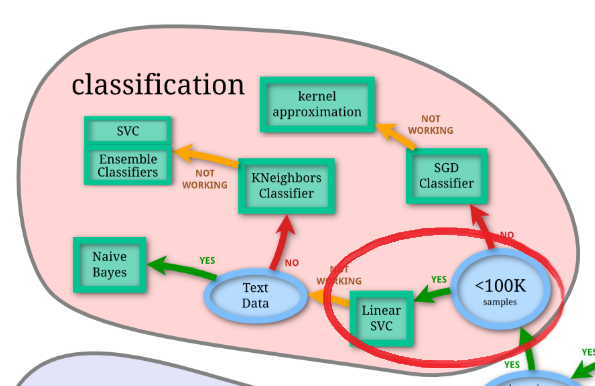
使用するアルゴリズムは、scikit-learnのアルゴリズム・チートシートに則って選択しました。
http://scikit-learn.org/stable/tutorial/machine_learning_map
MNISTはサンプル数が10万以下なので、”LinearSVC”(サポートベクターマシンの一種)をアルゴリズムとして使用してみます。
LinearSVCでの実行
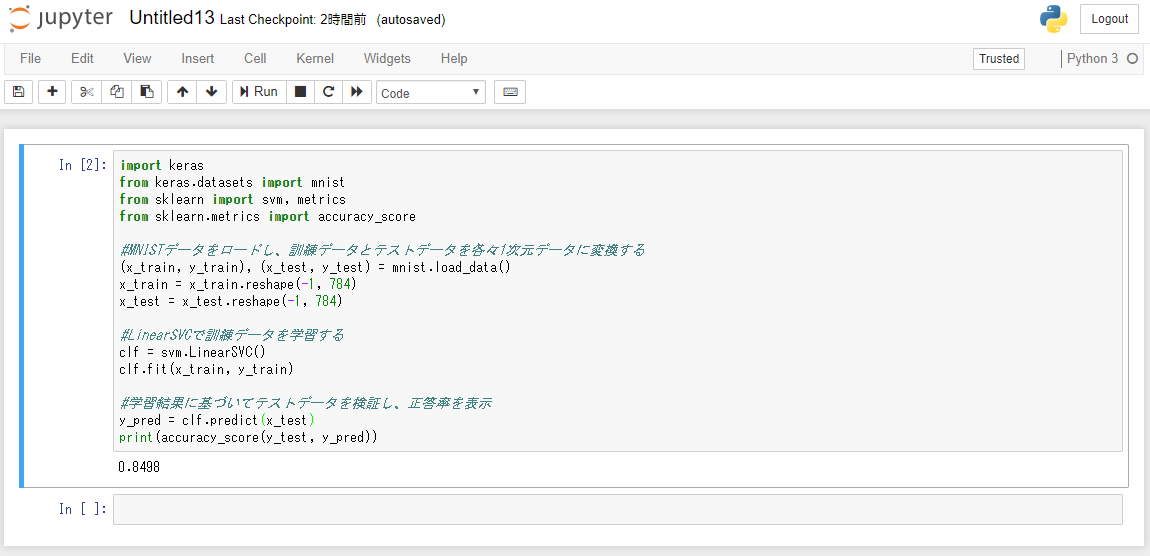
LinearSVCを使って書いてみたコードがこちら。fit と predict するだけのシンプルなものです。
import keras from keras.datasets import mnist from sklearn import svm, metrics from sklearn.metrics import accuracy_score #MNISTデータをロードし、訓練データとテストデータを各々1次元データに変換する (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(-1, 784) x_test = x_test.reshape(-1, 784) #LinearSVCで訓練データを学習する clf = svm.LinearSVC() clf.fit(x_train, y_train) #学習結果に基づいてテストデータを検証し、正答率を表示 y_pred = clf.predict(x_test) print(accuracy_score(y_test, y_pred))
ですがここで得られた正答率は僅か 0.8498。正答率が高いとは言えません。
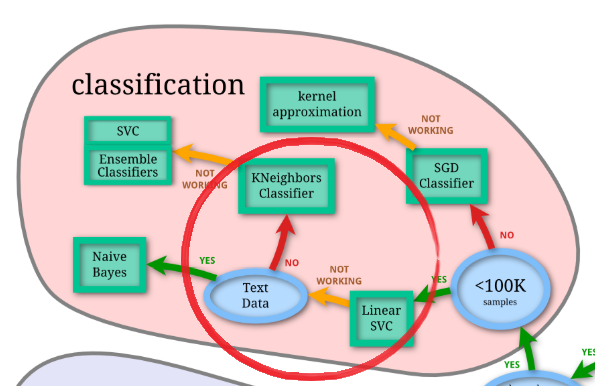
チューニングの方法は多々あると思いますが、アルゴリズムの選択を見直してみます。
KNeighbors Classifierでの実行
先ほど使用したものと同じチートシートから、LinearSCVの後の”NOT WORKING”に進み、行き着いた”KNeighbors Classifier”(K近傍法)を試してみることにします。
LinearSVCの部分をKNeighborsClassifierに置換して再度実行します。こちらは私の環境で実行に30分程度かかりました。
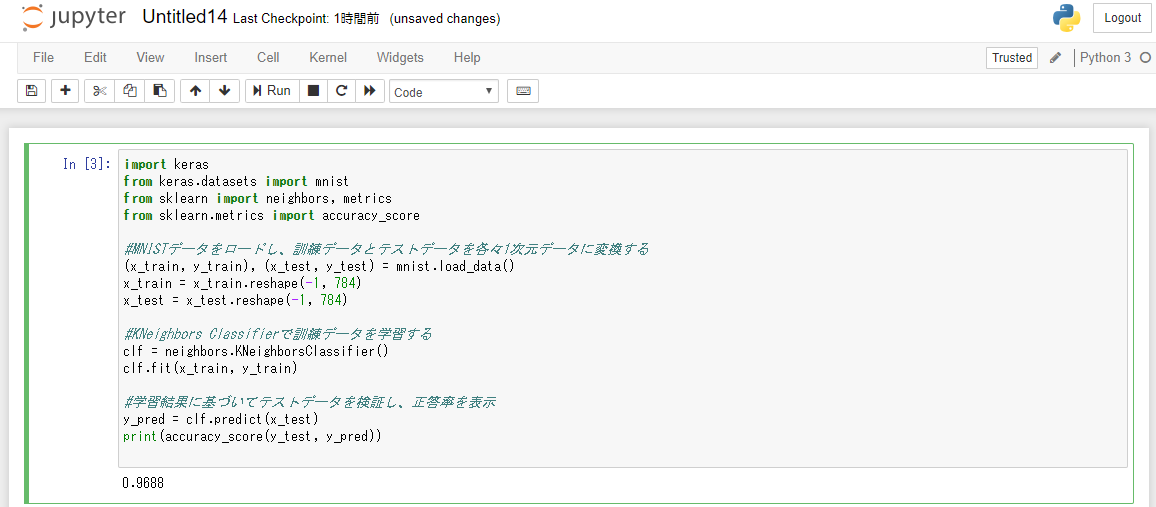
import keras from keras.datasets import mnist from sklearn import neighbors, metrics from sklearn.metrics import accuracy_score #MNISTデータをロードし、訓練データとテストデータを各々1次元データに変換する (x_train, y_train), (x_test, y_test) = mnist.load_data() x_train = x_train.reshape(-1, 784) x_test = x_test.reshape(-1, 784) #KNeighbors Classifierで訓練データを学習する clf = neighbors.KNeighborsClassifier() clf.fit(x_train, y_train) #学習結果に基づいてテストデータを検証し、正答率を表示 y_pred = clf.predict(x_test) print(accuracy_score(y_test, y_pred))
今度は正答率が0.9688にまで向上しました。
学習結果の利用
ここで得られた学習結果を保存します。
from sklearn.externals import joblib joblib.dump(clf, 'mnist_learn.pkl')
保存した学習結果をロードして、手書きの文字を読み込ませてみます。
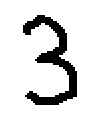
3.png

9.png
以下は”9.png”を読み込ませる例。
import cv2
from sklearn.externals import joblib
clf = joblib.load('mnist_learn.pkl')
img = cv2.imread('9.png')
img = cv2.resize(img, (28, 28)) #画像を28*28サイズに変換
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) #画像をグレースケールに変換
img = 255 - img #画像の白黒を反転する
img = img.reshape(-1, 784) #画像を1次元データに変換
res = clf.predict(my_img)
print(res)
“3”も”9″も正しく出力されました。
但し線が細いと正答値が得られないこともあり、まだまだ改良の余地がありそうです。