機械学習のフレームワークであるscikit-learnライブラリを用いて、日経平均株価を予測してみたいと思います。
LinearRegressionという線形回帰モデルによって実現することにします。
まず、日経平均株価のデータをダウンロード。
こちらのダウンロードセンターから、日経平均株価の「日次データ」を取得します。
https://indexes.nikkei.co.jp/nkave/index?type=download
このファイル “nikkei_stock_average_daily_jp.csv” を分析し、高値の予測を試みます。
ソースコードは以下。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression
#説明変数と目的変数の塊を作成する関数
def create_data(data):
term = 10 #過去何日分のデータを説明変数とするか
x = [] #term分の高値データを説明変数として格納
y = [] #xに格納された翌日分の高値を目的変数として格納
highest = list(data['高値']) #予測対象はデータの'高値'とする
for i in range(len(highest)):
x_tmp = []
for j in range(term):
d = i + j - term
x_tmp.append(highest[d])
if d < 0: break
if len(x_tmp) < term:continue
x.append(x_tmp)
y.append(highest[i])
return (x, y)
#日経平均データの読み込み
df = pd.read_csv("nikkei_stock_average_daily_jp.csv", encoding="sjis")
df = df.head(len(csv)-1) #最後の1行は不要データなので削除
#データを学習用とテスト用に分割
train_data = (pd.DatetimeIndex(df['データ日付']).year <= 2017) #2017年以前のデータは学習用
test_data = (pd.DatetimeIndex(df['データ日付']).year >= 2018) #2018年以降のデータはテスト用
train_x, train_y = create_data(df[train_data])
test_x, test_y = create_data(df[test_data])
lr = LinearRegression()
lr.fit(train_x, train_y)
lr_y = lr.predict(test_x)
plt.figure(figsize=(15, 10))
plt.plot(test_y, c='r') #実際の2018年高値データを赤色でプロット
plt.plot(lr_y, c='b') #予測した2018年高値データを青色でプロット
plt.savefig('nikkei_predict.png')
diff = abs(lr_y - test_y)
print("diff_average = ", sum(diff)/len(diff)) #誤差の平均を表示
print("diff_max = ", max(diff)) #誤差の最大値を表示
print("diff_min = ", min(diff)) #誤差の最小値を表示
ソースコードのコメントにもあるように、2017年以前のデータを学習データとし、それを基に2018年の高値を予測しています。
描画したグラフは以下の様になりました。赤線が実際の2018年データ、青線が予測した2018年データです。
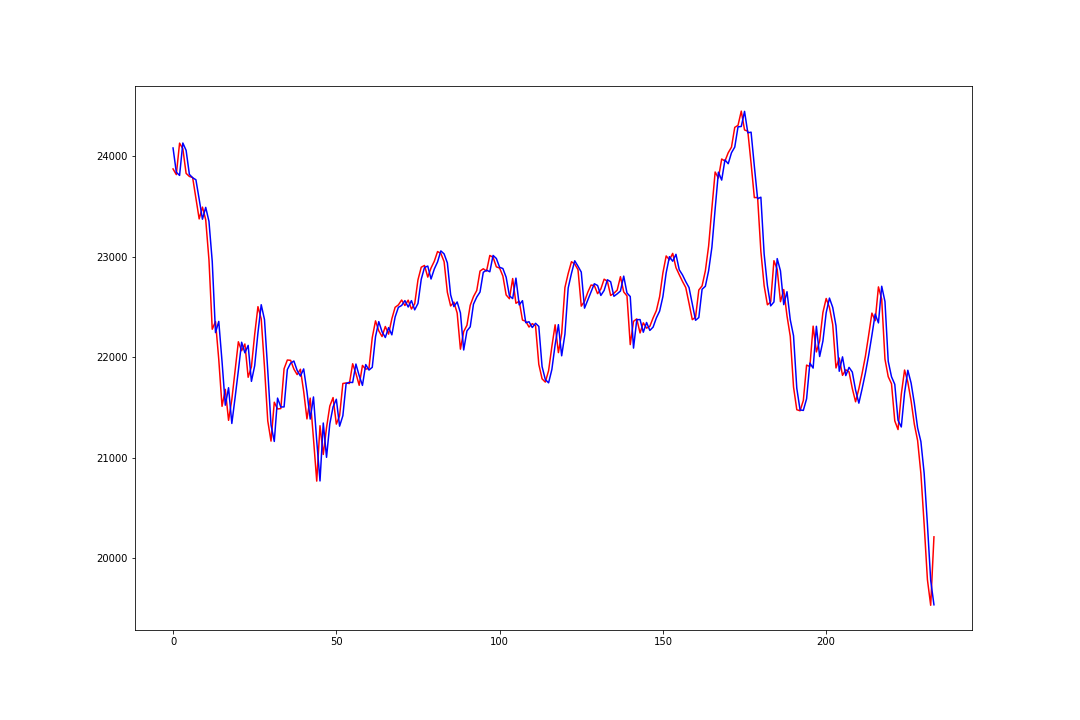
グラフを見た感じ、大きくは外れていないように見えます。
実際の誤差がどの程度あったのかを確認してみましょう。ソースコードの最終部分に、誤差の平均・最大値・最小値をそれぞれ表示するようにしておきました。
diff_average = 170.78997361069358
diff_max = 676.3308985423537
diff_min = 2.428238661676005
誤差の平均・最大値・最小値はそれぞれ、約170.8円、約676.3円、約2.4円という結果となりました。

