前回、CIFAR-10の画像データを試しに1枚表示してみました。
今後、この素晴らしいデータ群を、より応用的に参照できるようにするために、データの形式をより詳しく知りたいと思います。
格納されているデータの種類は?
CIFAR-10をチュートリアル通りにロードすると、辞書形式で取得することができます。
取得した辞書形式のデータdictから、キーの一覧をまず表示してみます。
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('data_batch_1')
#キー項目を列挙する
print(dict.keys())
結果はこのようになります。
どうやら、このデータは
- b’batch_label’
- b’labels’
- b’data’
- b’filenames’
の四つのカテゴリに分かれているようです。

b’batch_label’のデータ
一つ目のデータb’batch_label’の内容を表示してみましょう。
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('data_batch_1')
#キー項目 b'batch_label' のデータを表示する
print(dict[b'batch_label'])
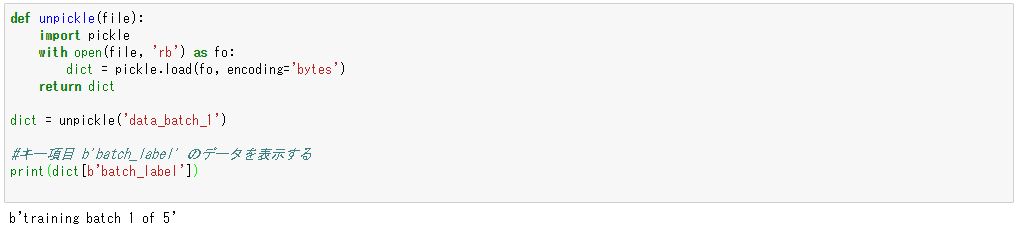
“training batch 1 of 5″という文字列が得られました。これはデータファイルそのものの簡単な説明であるようです。
b’labels’のデータ
今度は二つ目のデータであるb’labels’の内容を表示してみます。個々のイメージデータが何であるかを示すラベルであることが予測できるので、まずはサイズを確認し、データを表示してみます。
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('data_batch_1')
#キー項目 b'labels' のデータを表示する
print(len(dict[b'labels']))
print(dict[b'labels'])
結果はこのように表示されました。データの総数は10,000個で、ラベルが整数型の配列で格納されているのがわかります。
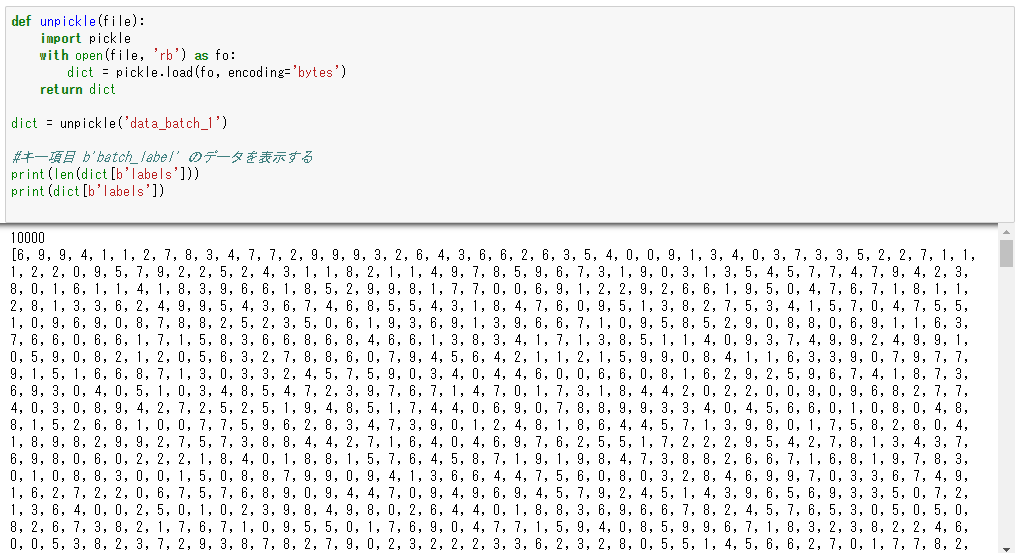
6=蛙、9=トラック、9=トラック、4=鹿、・・・と続いているようですね。
b’data’のデータ
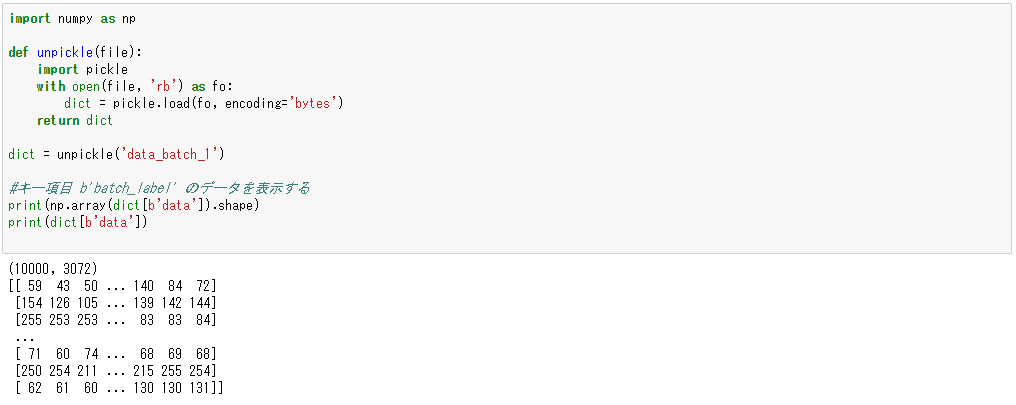
さらに三つ目のデータであるb’data’の内容を表示してみます。今度は個々のイメージデータが配列で格納されていることが予測できるので、行列の形状を確認したのちに、データを表示してみます。
import numpy as np
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('data_batch_1')
#キー項目 b'data' のデータを表示する
print(np.array(dict[b'data']).shape)
print(dict[b'data'])
結果はこんな感じ。3072個の要素を持つデータが10,000個格納されているのがわかります。
b’filenames’のデータ
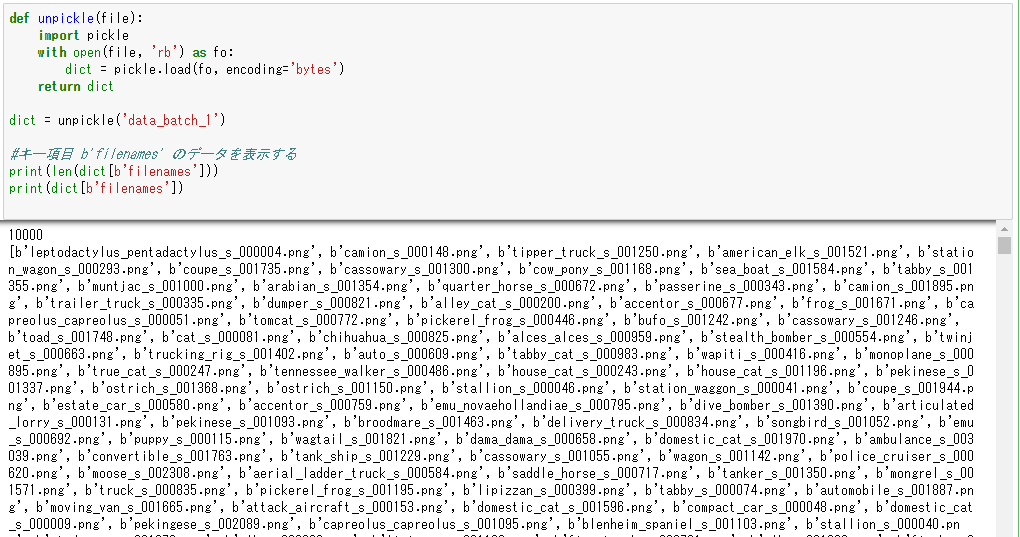
最後に四つ目のデータであるb’filenames’の内容を見てみます。こちらも件数と個々のデータの両方を表示してみます。
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('data_batch_1')
#キー項目 b'filenames' のデータを表示する
print(len(dict[b'filenames']))
print(dict[b'filenames'])
結果を見ると、個々の画像データの具体的なファイル名であるらしいことがわかります。
まとめ
CIFAR-10のデータから、”data_batch_1″のデータ形式を見てみました。この結果、
- ラベルは b’labels’
- データは b’data’
にそれぞれ格納されていることがわかりました。
実際の機械学習では、この二つを学習させていくことになるでしょう。

